
Wenn Code vermehrt von Maschinen als von Menschen generiert wird, wird sich auch der Prozess der Softwarentwicklung grundlegend verändern. Hierzu ein paar Gedanken …

KI & CODE - Windsurf Praxistipps
Was ist Windsurf?
Windsurf ist ein Programmierwerkzeug / eine IDE von Codeium, die auf einem Fork von VSCode realisiert ist. Es gibt artverwandte Tools wie Cursor und viele mehr, die ebenfalls zum Ziel haben KI für die Programmierpraxis erschließen. Alle Tools bieten jeweils Vor- und Nachteile. Um einen ausgiebigen Vergleich soll es an dieser Stelle jedoch nicht gehen.
Mit Windsurf wurden verschiedene LLM Modelle (etwa Claude 3.5 Sonnet, GPT-4o oder Deepseek V3 …) integriert und in agentic chatbot überführt. Die KI Skills können dann für die Arbeit am Projekt als Hilfestellung oder auch zur Generierung von Code verwendet werden.
Windsurf kombiniert verschiedene Funktionen: ein indiziertes Kontextwissen / Gedächtnis zur vorliegenden Codebasis (im Projekt), Chat-Interaktion mit dem LLM und Workflows (‘Flows’) für die Kombination verschiedener Aktionen und Interaktionen. Auf diese Weise lassen sich generative oder diskursive Aufgaben via IDE ausführen. Das funktionale Spektrum geht weit über Chats hinaus. Die ‘agentic’ KI kann Terminal-Befehle absetzen (etwa um im Projekt neue Module zu installieren), Dateien lesen, editieren und schreiben, Bilder interpretieren (praktisch für UI / Design -Diskussionen) und Recherchen im Internet anstellen (z.B. um eine Dokumentation der aktuellen Nuxt-Version einzusehen). Dieser tiefgreifende Funktionsumfang kann und sollte natürlich Sicherheits- und Datenschutzbedenken provozieren, dies ist jedoch nicht das Thema in diesem Beitrag.
Windsurf IDE
Wenn ich im Windsurf Chat nach einer Übersicht der Windsurf Skills & Limitierungen frage, erhalte ich:
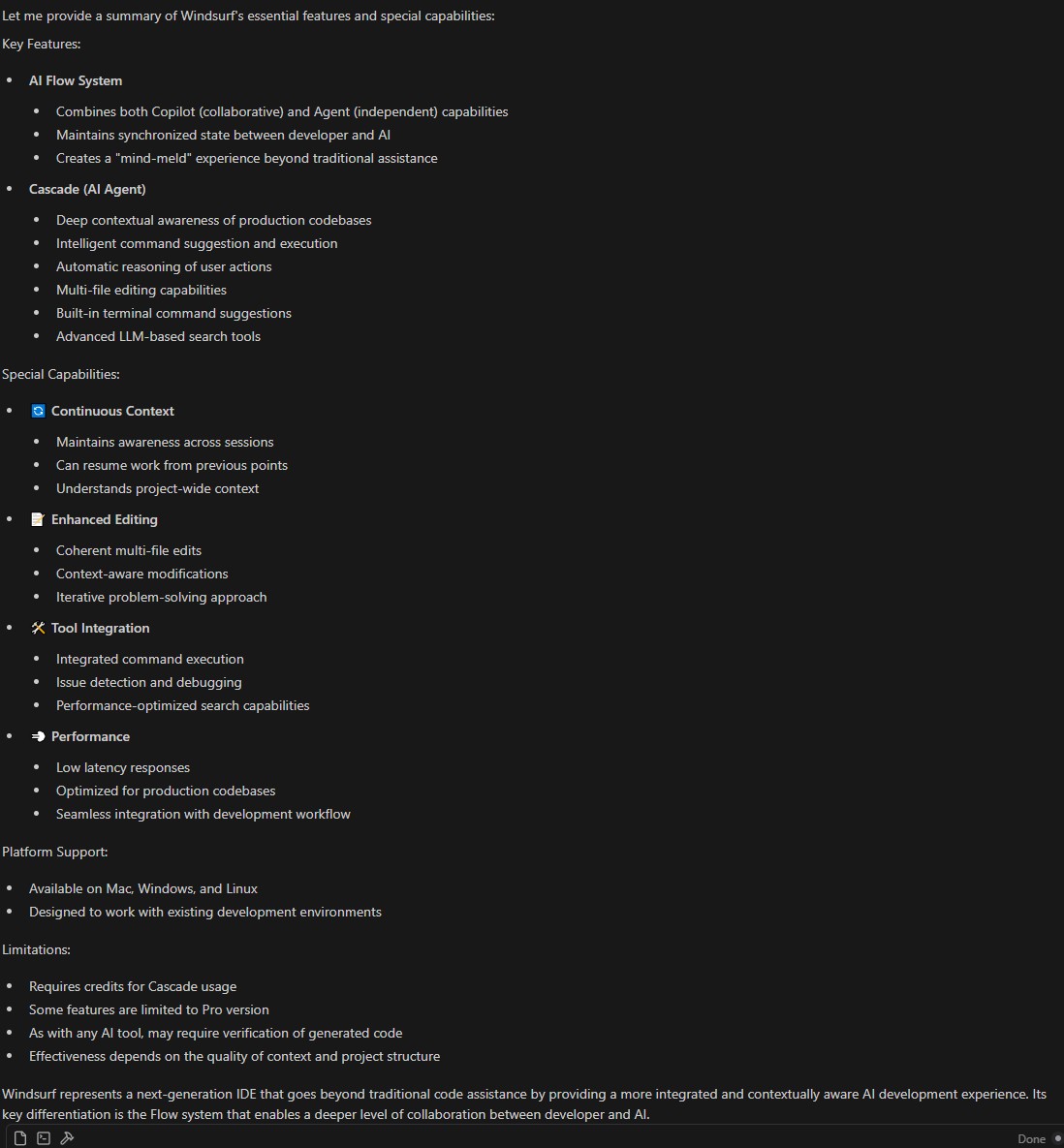
Windsurf über Windsurf
Agentic / Gen AI in der Entwicklungspraxis
Mit dem Funktionsumfang von Windsurf kann man durchaus einiges anstellen, aber nicht alles klappt stets so wie erwartet … zum einen hängt die Qualität des Ergebnisses nicht nur von der KI ab, sondern auch vom Benutzer. Erfahrung hilft hier definitiv weiter. Zum anderen existieren aber noch grundsätzliche Limitierungen und Probleme für die Entwicklungspraxis mit KI, die zum Teil in der Natur der Sache liegen (etwa der Funktionsweise von LLMs) oder mit der Maturität eines Tools zusammenhängen (fehlende Funktionen, Qualität, Performanz etc.).
Moderne Entwicklungsprojekte können mitunter sehr komplex sein. Dies betrifft Menschen ebenso wie Maschinen. Die Arbeit an komplexeren Projekten führt die KI (aber auch Menschen) oft an ihre Grenzen. Typische Probleme und Limitierungen der KI (in der generativen Kollaboration) sind dann etwa …
- Vollständigkeitsprobleme: Teile des Codes werden durch die KI geändert, aber wichtige Abhängigkeiten nicht vollständig berücksichtigt. Die Feature-Implementierung bleibt lückenhaft und ist somit nicht verlässlich.
- Interpretationsprobleme: Die KI ist nicht in der Lage das Anforderungsprofil oder Anweisungen richtig zu interpretieren und macht Dinge, die nicht zielführend sind, aber evtl. erst spät auffallen.
- Mangel an Statusempfinden: Wenn ich eine KI-Sitzung beginne, weiß der ‘Automat’ nicht wirklich, ob wir in einem frühen oder fortgeschrittenen Stadium des Projektes unterwegs sind. Was genau bereits fertig ist, was noch konkret fehlt und was eventuell noch geplant wäre, all das kann nicht eindeutig beurteilt werden. Für diese ja qualitative Beurteilung ist der Mensch als Interaktionspartner zwingend nötig.
- Informationsmangel oder Erfahrungsdegradierung: Wichtige Rahmenbedingungen werden häufig nach einer Weile vergessen, so dass es zu Fehleinschätzungen oder überflüssigen Aktionen kommt. Ein simples Beispiel: wenn ich in einem Projekt etwa ‘yarn’ benutze, neigt das KI-Programmierteam häufig dazu, wieder auf ’npm’ zurückzufallen. Solche einfachen Fehler können Nerven kosten.
- Evidenzbasierter / Selbstreferenzieller Bias: Die Code-Generierung wird zunehmend zur eigenen Realität, zum sich potenzierenden Kontext, wodurch die KI immer tiefer in ein ‘Rabbit Hole’ von Annahmen geraten kann. Es optimiert z.B. bestimmte Bereiche immer weiter und immer tiefer und vernachlässigt dabei überproportional andere, eigentlich wichtigere Aufgaben. Dies liegt in der Natur der Sache.
- Kreativitätsmangel: LLMs sind antrainiert auf dem Bestehenden und werden auf Basis von Wahrscheinlichkeiten erst gut. Ein Folgeproblem ist nun, dass wirklich ‘Neuartiges’ auf dieser Grundlage nur durch Re-Kombination und zusätzliche Einflussnahme entstehen kann. Dies gilt für Programmierung ebenso wie für Bildgenerierung. Aber hierzu eine Meinung: Kreativverantwortungen sollte man nicht an Wahrscheinlichkeitsmaschinen delegieren, wenn man nicht enttäuscht werden will :)
- Probleme mit der Vergangenheitsbewältigung: LLMs sind nunmal in großen Teile auf Basis der Vergangenheit antrainiert. Aktuelle Best-Practices werden also nicht immer top-aktuell umgesetzt, da ein Modell etwa die Best Practices von vor zwei Jahren für optimal hält. Durch erweiterten Kontext kann man dem entgegenwirken, aber man sollte sich dies vor Augen halten, wenn man ’top notch’ Ansätze generieren lassen will.
- Kosten / Nutzen: Qualität kostet. Das ist beim Einsatz von LLMs (und auch bei Windsurf) nicht anders. Wenn viel Kontext verarbeitet wird, die besten Modelle verwendet werden und aufwändige Interaktionen mit Tools und Internetrecherche einhergehen, dann können bessere Ergebnisse entstehen. Diese sind aber teurer. So ist also auch die Arbeit mit KI immer ein Tradeoff zwischen Kosten und Nutzen.
Festzuhalten ist, dass KI-basierte Codegenerierung oder agentenbasierte Kollaboration Limitierungen hat und nicht frei von Problemen ist. Dies gilt natürlich auch für Windsurf. Doch wie nutzen wir nun das bestehende Potenzial (trotzdem) optimal?
Hier sind einige Tipps & Tricks, die ich auf Basis meiner persönlichen Erfahrungen mit Windsurf gesammelt habe.
Windsurf Tipps für die Praxis
1. Kontext und Kontinuität aktiv beeinflussen
Eine der größten Herausforderungen bei der Arbeit mit KI-gestützten Entwicklungstools ist die limitierte Kontextmenge, die bearbeitet werden kann. Zunächst sind LLM’s, also KI-Modelle limitiert im Sinne der Tokens, die in einem Prompt oder einer Session verarbeitet werden können. Doch auch, wenn man eine Vektordatenbank anklemmt, kann dieses Gedächtnis nicht unendlich erweitert werden, was die Lernfähigkeit innerhalb einer Session betrifft. Man kann Informationen durchsuchbar machen, was aber nicht bedeutet, dass diese automatisch im derzeitigen ‘Gedächtnis’ innerhalb der iterativen Arbeit jederzeit bewusst einbezogen werden. Kontext ist vielleicht alles - und dieser ist heute limitiert.
In einer Windsurf-Chatsession bedeutet “Kontext” alles, was die KI über unser Projekt und unsere Absichten weiß: den Code, den sie reflektiert, die Entscheidungen, die wir bereits getroffen haben, und die Richtung, in die wir voranschreiten wollen. Ähnlich wie ein neuer Teammitarbeiter braucht die KI diesen Kontext, um sinnvoll mitarbeiten zu können.
Die Herausforderung dabei: Der Kontext einer KI-Chatsession ist naturgemäß begrenzt. Die KI “vergisst” nach einer gewissen Zeit, worüber wir gesprochen haben – wie ein Kurzzeitgedächtnis. Hier einige praktische Ansätze, die sich in meinem Workflow bewährt haben, um diese Begrenzung zu überwinden oder mindestens abzumildern:
Markdown als Gedächtnisstütze
Ich dokumentiere relevante Ergebnisse, wichtige Entscheidungen oder Anforderungen in *.md Markdown-Dateien, z.B. in einem /docs/* Ordner im Repository. Markdown wird in vielen Tools verwendet und kann besonders gut von LLM’s verarbeitet werden.
Die KI weise ich an, wichtige Zwischenstände ihrerseits zu dokumentieren oder bestehende Dateien nach jeder Iteration zu reviewen und wenn nötig zu aktualisieren. Im besten Falle entsteht so eine systematische Dokumentationsstruktur mit aktuellen Informationen, Referenzen zu Zusatzkontexten, Anforderungs- oder Planungsdokumenten, Entscheidungen und dem Status. Dieser Informationsfundus dient (als Teil der Codebasis) der KI als zusätzliches “Langzeitgedächtnis”, welches Kontext zwischen verschiedenen Entwicklungssessions (~ Chats) vermitteln kann.
Durch ein Referenzieren von Dateien mit @-Mentions kann ich der KI schnell den notwendigen Kontext wiedergeben bzw. anpinnen. So kann ich zu jeder Zeit auf eine wichtige Information referenzieren und den Kontext des Prompts präzisieren.
Längere Sessions mit vielen KI-Interaktionen werden früher oder später extrem träge. Das ist durchaus normal und entsteht durch den immer größer werdenden Kontext im Chat bzw. in der LLM Interaktion. Das stört ungemein in realen Arbeitsabläufen, weshalb das ‘Neustarten’ einer frischen Konversation vieles verbessert. Aber - in diesem Falle steht man quasi wieder ohne Gedächtnis da: das Tool ist wieder doof und unreflektierte Aktionen sind zu vermuten. Genau hierbei helfen nun unsere Dateien! Mit gezielten @-Mentions kann ich relevante Ordner / Dateien in den Kontext holen, die dann dem Gedächtnisverlust entgegenwirken.
So übergebe ich essentielle Infos von einer Session zur anderen und kann damit übrigens auch den Fokus neu ausrichten, etwa wenn in einer Konversation immer wieder falsche Schlussfolgerungen gezogen wurden.
Systemdesigns besprechen
Markdown kann übrigens nun vielseitig und kreativ verwendet werden, um mehr als nur Text zu besprechen. Ich nutze bspw. mermaid als Möglichkeit zum Austausch ganzer Datenmodell-Entwürfe zwisch Mensch und Maschine. Dabei schaue ich z.B. auf Bildchen (ER-, Interaktionsdiagramme etc.) und die KI interpretiert und schreibt die dafür nötige Syntax. Nett ist dabei, dass wir beide auf Basis dieser Informationsgrundlage diskutieren können. Auf diese Weise kann man komplexe Systementwürfe oder Problemstellungen besprechen und auch in Abarbeitungspläne überführen (ohne das große Ganze aus dem Auge zu verlieren).
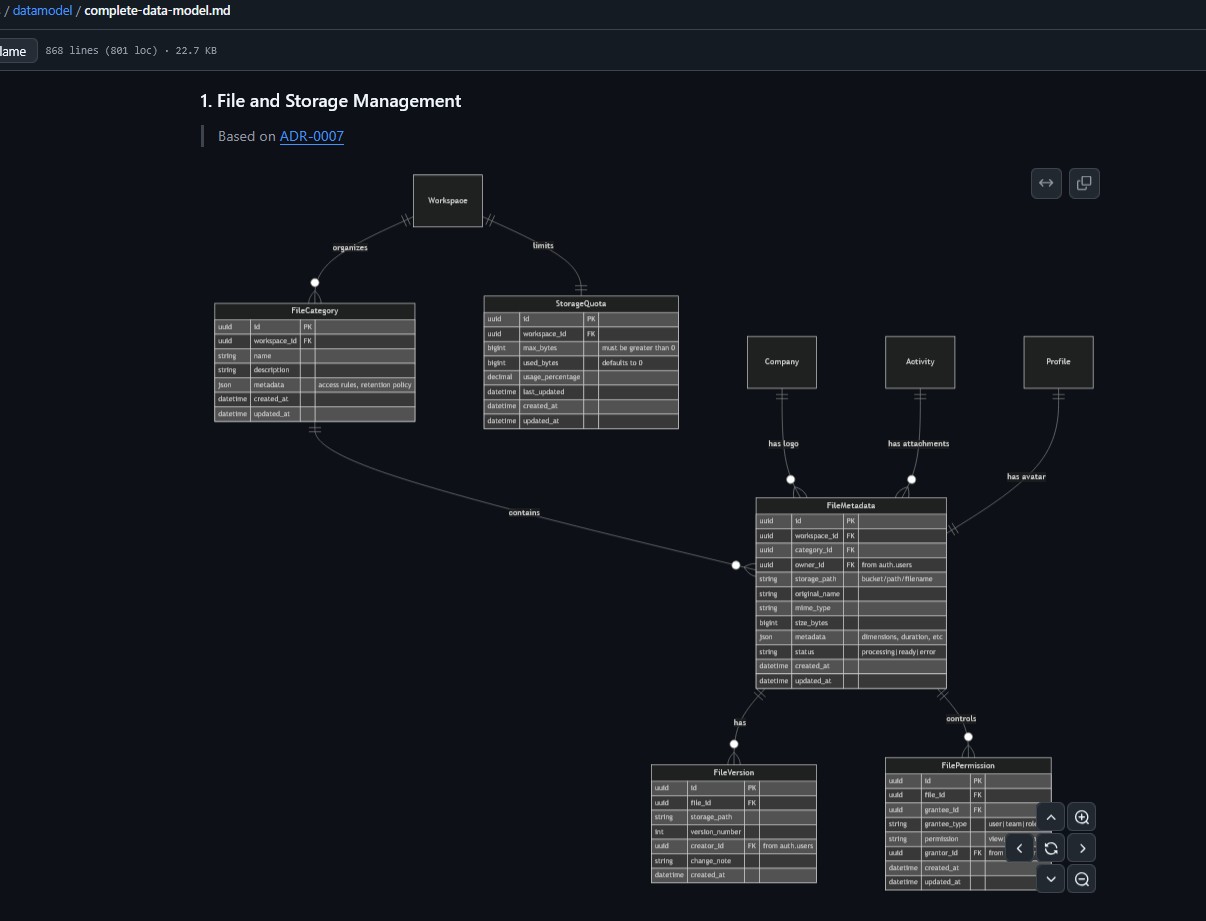
KI Interaktion mit Diagrammen im Repository
](/images/blog/ai_dev_usingmermaid.jpg)
Mermaid Syntax und Digramm / via mermaidjs
Todo-Listen & Backlogs
Ein Produktmensch wie ich braucht schließlich ein Backlogs, nicht wahr? Nun … Geordnete Todo-Listen und Backlogs können wunderbar in separaten Markdown-Dateien gepflegt und abgehakt werden. So bleiben der Agent und ich im Optimalfall auf die selben Aufgaben fokussiert und wir verhindern, dass sich die KI in nicht relevanten Abläufen verliert oder gänzlich anderes macht als erwartet. Eine docs/todos.md (als Beispiel), ist ebenfalls in Markdown-Syntax geschrieben und dient als “Navigationskarte und Checklist” für unsere Entwicklungsreise bzw. entlang unserer Anforderungen.

Gemeinsame Todolisten mit der KI
Man muss die KI aber immer wieder aktiv darauf hinweisen und dazu anhalten, nach der Erledigung von X auch X als erledigt markieren. Denn die pure Existenz einer Datei ändert zunächst nicht viel, erst die aktive Einbeziehung in den Kontext macht den Unterschied. Ich lasse auf diese Weise die KI ganze Aufgabenpakete selbst runterbrechen, gegenvalidieren und abhaken, allerdings muss dies natürlich kontrolliert werden.
Standards und DEV-Setups
Ich beginne oft damit, eine docs/standards.md mit wichtigen ext. Links zu Dokumentationen, Referenzen zu anderen Dateien (etwa docs), Übersichten, gewünschten UI-Pattern, Architekturentscheidungen oder konventionellen Routinen je Projekt aufzubauen. Neben Einstellungen für die KI (dazu später mehr), dient diese Datei dazu, dass auch neue Erkenntnisse zu Do’s and Dont’s oder Code-Templates dokumentiert werden können.
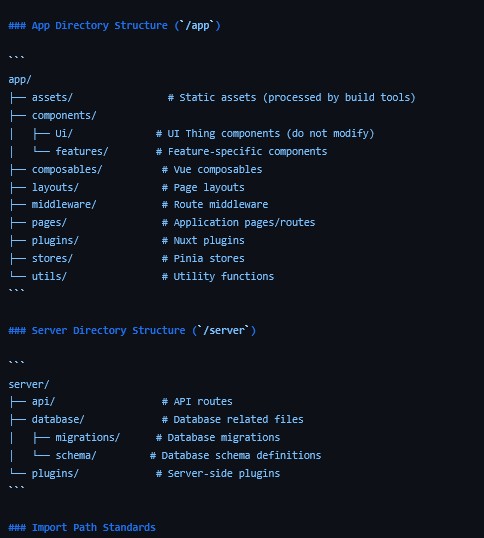
Projektstruktur als möglicher Standard
Wenn ich eine solche Datei dann in einer neuen Konversation in den Kontext hole, ist die KI schon ganz gut aufgegleist. Doch es fehlt unter Umständen noch die eigene projektspezifische Erfahrung, wie etwa Lerneffekten auf Basis von eigenen Fehlern. Hierfür benutze ich auch Markdown …
Session-Handover
Der Code-Automat soll sich selbst eine Übergabe von der einen zur nächsten Session erstellen, bevor ich die Sitzung beende. Etwa auf Basis einer docs/handover.md-Datei. Ich halte sie dazu an, stetig oder abschließend den aktuellen Stand, nächste Prioritäten oder offene Baustellen, Learnings und wichtige Zusatzinfos autonom zu pflegen. Dies mit dem Ziel anderen Teammitgliedern oder Agenten ein prägnantes, aber solides Onboarding zu ermöglichen. Dies kann im besten Falle dazu führen, dass unmittelbar an die letzte Session angeknüpft werden kann und die Quintessenz neuer Einsichten erhalten bleibt.
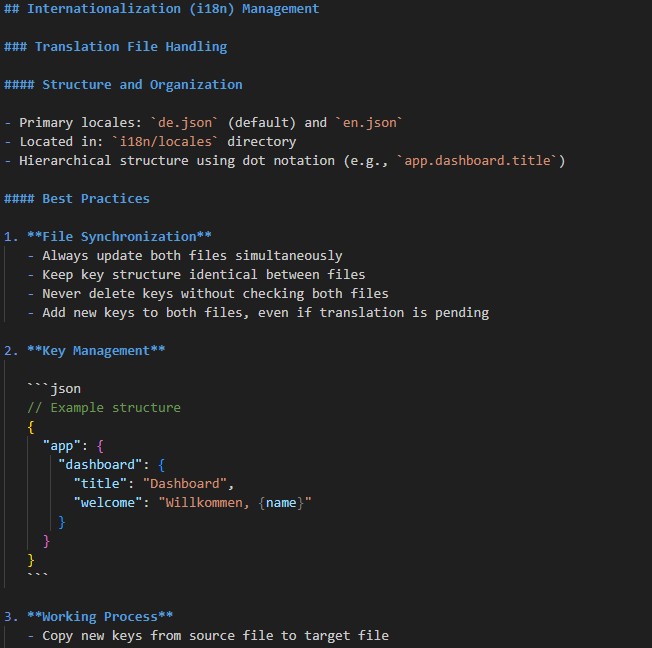
Handover-Beispiel von der KI an sich selbst
Im Beispiel oben ist zu sehen, wie der Agent seine Fehler im Umgang mit Übersetzungsdateien festhält und die neu gewonnene Erkenntnis (’lieber besser so…’) für die Nachwelt dokumentiert. Es kann viel Ärger ersparen, wenn solch neue Erkenntnisse sessionübergreifend und somit konsistent angewandt werden.
Asimov’sche Robotergesetze
Um Vorgänge und Standards grundlegend festzulegen, kann man sich der Einstellungen für den aktuellen Arbeitsbereich und globalen Tool Einstellungen bedienen. Windurf bietet inzwischen (von Nutzern angefragte) Möglichkeiten an, wichtige Grundsäztze, Regeln usw. einstellen zu können. Zuvor konnte dies nur auf Basis von Dateien simuliert werden. Sprich, Windsurf hat von den Datei-Tricks (wie eben beschrieben) gelernt und auf ein Feature-Level gehoben. In diesen Einstellungen kann man frei Regeln 1. - n. niederschreiben, die einen grundlegenden Kontext bilden und dem Code-Agent dann einen Rahmen vorgeben.
](/images/blog/user-defined-memories.png)
KI - Regeln einstellen / via codeium.com
Globale Regeln kann man etwa nutzen, um bestimmte Konventionen für die KI niederzuschreiben, wie … ‘Make in-line comment on top of every file to explain the purpose of the file and important context information’ oder ‘If you need more information on requirements or miss context information for a task at hand, ask the team for help before working on a task.’ usw. Die globalen Einstellungen sollten zu allen Projekten passen können, die man eventuell bearbeitet.
Projektspezifische Workspace Regeln kann man dafür verwenden, auf projektspezifische Besonderheiten, bestimmte technologische Konventionen oder relevante Dokumentationen hinzuweisen. Ich platziere hier auch meine Hinweise darauf, welche markdown-Dateien für dieses Projekt relevant sind, welche autonom angelegt oder aktualisiert werden sollen oder was es für den Prozess im Projekt zu beachten gilt.
- Zwischenfazit für die mehrschichtige Konfiguration:
- Workspace-Settings für projektspezifische Standards, Dokumente und Richtlinien
- Globale AI-Settings für übergreifende Entwicklungsparadigmen und allgemeine Anweisungen
- Markdown-Dateien zur zusätzlichen Kontext-Kontrolle, etwa Backlog, Standards, aber auch Learnings in
docs/learnings.md - Manche Informationen sollte der Agent selbsttätig aktualisieren, Review ist allerdings immer nötig.
- @-Mentions für präzise Fokussierung auf relevante Kontexte
- Verlinkung innerhalb von Dokumentationen, z.B. auf Framework-Dokumentationen oder zu projektspezifischen Dateien
- Einbindung von Diagrammen und Zusatzinformationen ist zu empfehlen (je nach Komplexität des Projektes)
Durch systematische Herangehensweisen schaffen wir ein “erweitertes Gedächtnis” für die KI-Zusammenarbeit. Statt bei jeder Session von vorne beginnen zu müssen, können wir effizient dort weitermachen, wo wir aufgehört haben. Das Auslagern von wichtigen Informationen in Dokumente steigert die Effizienz in der konversationalen Arbeit.
2. SCOPE ist alles
Eines der aus meiner Sicht größten Probleme ist es, den Anforderungsumfang eines Projektes auf dem Radar zu halten und kontrolliert umzusetzen. Wie bereits erwähnt, driften die Agenten naturgemäß ab, vergessen Dinge, verstehen etwas falsch oder wurschteln sich einfach durch unerwünschte Gefilde. Hier also ein paar zusätzliche Hinweise, wie der gewünschte und der realisierte ‘Scope’ kontrollierter beieinander bleiben.
Architekturentscheidungen
Architekturentscheidungen können dediziert dokumentiert werden, z.B. nach ADR-Konvention. Man kann diese nach Status sortieren, so dass der KI klar ist, was akzeptiert wurde und was nicht. Ich lasse ADR-Dokumente vollständig erstellen, diskutiere oder korrigiere diese dann und verlinke wichtige Entscheidungen in den Standards.
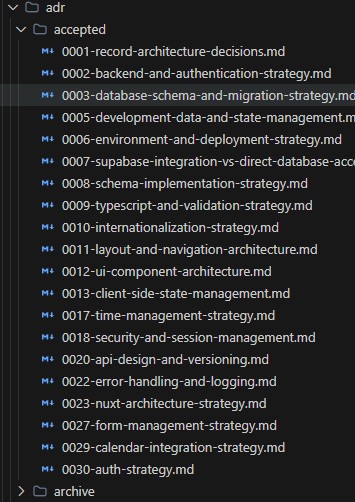
Architecture Desicion Records / ADR nutzen
Inkrementelle Planung generieren
Wenn man ein bestimmtes Feature von der KI umsetzen lassen will, kann man sich auf Basis der Anforderungen zunächst einen detaillierten Umsetzungsplan erstellen lassen. Sobald die KI den feature-xyz-plan.md geschrieben hat, lassen sich häufig grobe Fehlannahmen, Priorisierungsfehler oder andere Schwächen aufdecken. Diese können dann vor der eigentlichen Umsetzung behoben werden. Diese kleinschrittige Planung führt die KI bei der Umsetzung in einen stärkeren Determinismus. So kommen meist bessere Lösungen zustande und man spart letztlich viel Zeit (und credits).
Übrigens: In der menschlichen Realität würde dies potentiell sehr lange dauern. In der Maschinenrealität ist ein solcher Zwischenschritt sofort erledigt. Mein Lesen und Schreiben verursacht die größte Latenz in diesem Zusammenhang.
Regelmäßige Realitätschecks einfordern
Dokumente und Pläne können zwar gut klingen, müssen aber nicht immer mit der Codebqualität und Vollständigkeit übereinstimmen. Es lohnt sich also immer wieder, regelmäßig einen Blick auf die Realität einzufordern:
- Somit: Häufig zur Code-Recherche auffordern, um in der Konversation das Wissen über den IST-Zustand frisch zu halten. Windsurf kann hier grundsätzlich punkten und viel Code ‘konsumieren’.
- Im Zuge von Code-Recherchen lassen sich Auffälligkeiten direkt als Todo oder Optimierungspotential protokollieren.
- In diesem Kontext sind zuvor generierte und hoffentlich relevante In-Line Kommentare übrigens sehr nützlich!
- Die KI sollte Abhängigkeiten / Constraints vor der Bearbeitung überprüfen. Auch ein Review ist sinnvoll, denn häufig wurde etwas nicht bedacht oder falsche Annahmen wurden getroffen.
- Auf wichtige Rahmenbedingungen (wie etwa bestimmte Abhängigkeiten) sollte man auch während der Anweisung bzw. im Prompt eingehen. Bspw. macht es Sinn, die KI hin und wieder auf die
package.jsonoder wichtige Konfigurationsdateien aktiv hinzuweisen. - Typescript, Linter und Prettier nutzen: Warnings zu Codestyle, Typisierungsproblemen oder Fehlermeldungen lassen sich komfortabel weiterverwenden. Hier zahlt sich der IDE-Fork aus. Im Chat kann man direkt auf alle Probleme mit
@current_problemshinweisen. In früheren Versionen musste man hier noch mit Copy & Paste arbeiten.
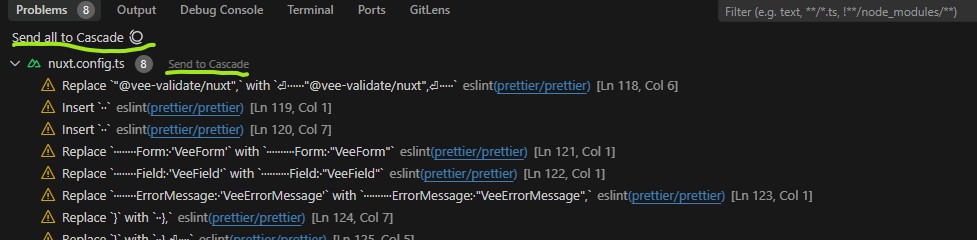
Mit dem Agenten auch mal über Probleme sprechen
Bilder sagen mehr als 1000 Worte
Auch wenn nicht jedes Modell multi-modalen Input verarbeiten kann, sollte die Arbeit mit visuellen Informationen nicht ausgelassen werden. Gerade wenn es um Designaspekte, Usability oder Wording-Probleme geht, sind Bilder enorm hilfreich.
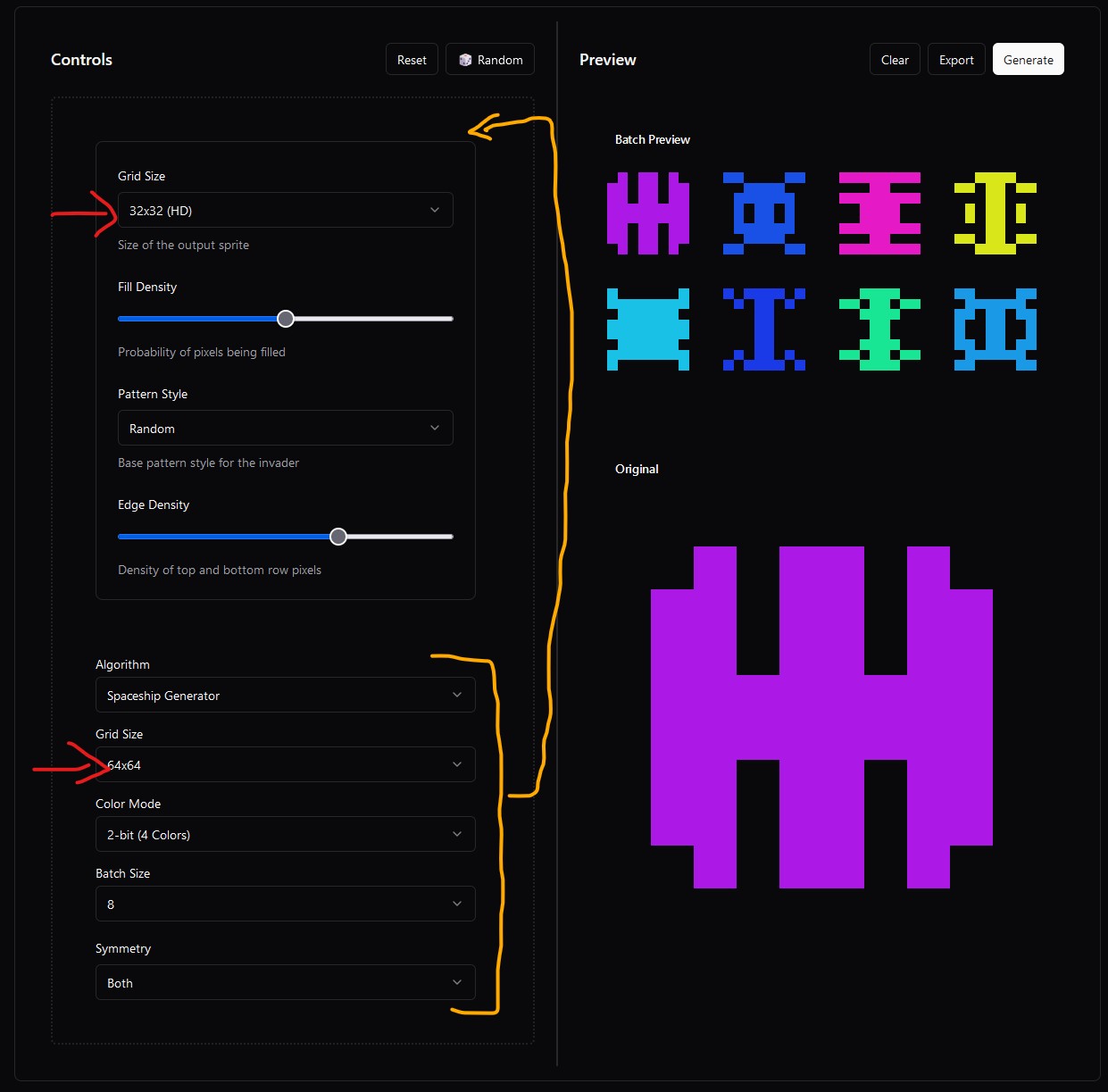
Durch Screenshots auf Probleme hinweisen
In dem obigen Bild habe ich als frühes Testprojekt eine Sprite-Generator-App generieren lassen. Probleme habe ich direkt visuell angesprochen, was erstaunlich gut funktioniert hat. Ich würde sogar sagen, dass Bilder besser funktionieren als Worte. Sogar Texte etc. werden verlässlich interpretiert, so dass z.B. Consolen-Ausgaben vollständig mit verwendet werden können. Auf diese Weise lassen sich nicht nur Mock-Ups besprechen, sondern sogar komplexe Problemlagen.
Zusatztipps im Kontext von Bildmaterialien:
- Man kann die KI auch dazu bewegen, ein curl-script zu schreiben, welches gute Testbilder von unsplash passend zum Inhalt herunterlädt und z.B. für eine Landingpage verwendet.
- Ebenso kann man SVG’s generieren lassen und so ein vollständig neues Grafik-/ Icon-Set erstellen lassen.
3. Sonstige Hinweise für die Praxis
Git nutzen
- Man sollte immer vom worst-case ausgehen und von daher häufig Commits erstellen und (etwa auf Feature-Ebene) einen neuen Feature-Branch anlegen
- Branches und Git-Historie sind hilfreich, um der KI etwa alte Arbeitstände mit dem aktuellen Ansatz zu vergleichen (falls nötig)
- Code generierende Werzeuge mit Terminal-Skill eignen sich natürlich wunderbar, um erstklassige Commit Messages zu delegieren ;)
MCP
Mit Windsurf kann via MCP, also einem Protokoll um ‘Kontexte’ an das LLM weiter zu reichen, zusätzliche Grenzen ausgelotet werden. Mehr Info auch hier. Auf diese Weise können externe Tools via API in die Arbeit integriert werden.
Geduld im Terminal einfordern
Man kann auf ein gemeinsames Terminal mit Cascade ‘schauen’ - die KI kann dort Dinge ausführen, der Mensch auch.
Angenommen, man startet eine App mit yarn dev, dann kann es mitunter dauern, bis alle Schritte durchlaufen sind bis im Browser die Client-App vollständig geladen ist.
Cascade scheint hier oftmals ungeduldig und wendet den Blick zu früh ab. So verpasst es diese oder jene Fehlermeldung, die auftreten kann.
Hier hilft nur, das Verpasste entsprechend zu kopieren oder das geduldige Abwarten einzufordern.
Fazit
Die Arbeit mit Windsurf und KI-gestützter Entwicklung erfordert vermutlich ein strategisches Umdenken in unseren Entwicklungspraktiken.
Der Schlüssel zum Erfolg liegt in der geschickten Melange menschlicher Expertise & Kreativität und den neuen Möglichkeiten von generativer KI. Durch strukturiertes Kontextmanagement, präzise Kommunikation und systematische Qualitätssicherung können wir die Entwicklungsqualität einigermaßen gut kontrollieren, die Geschwindigkeit deutlich steigern. Windsurf im Speziellen verfügt über ein solides Funktionsset und kann bereits sehr nützlich sein. Doch komplexe Projekte lassen sich nicht einfach kontrollieren und schon gar nicht vollständig autonom generieren. Um also komplexere Anwendungen in der Kollaboration mit KI zu entwickeln, sind Kniffe, Vorkehrungen und Erfahrung unabdingbar.
Besonders nützlich sind etwa:
- Die Etablierung eines durchdachten Dokumentations- und Kommunikationssystems hilft dem Gedächtnis auf die Sprünge.
- Wenn die Konversation hakt, bereite ein Handover vor.
- Markdown ist exzellent für KI-Verarbeitung geeignet und kann gut verwendet werden, um Informationen zu dokumentieren, zu verlinken usw.
- Bestimmte Dateikonventionen kann man systematisieren, um effizienter und qualitativ konsistenter zu arbeiten. Etwa durch eine standards.md
- Die Kombination aus projektspezifischen, globalen und dateibasierten Kontexten sollte gezielt eingesetzt werden, um aktuellen Defiziten von KI(-Tools) entgegenzuwirken.
- Der Einsatz von Diagrammen (etwa auf Basis von mermaid) und ADRs für Architekturentscheidungen eignen sich sehr gut.
- Backlogs und Todos sollten stetig aktualisiert werden (von Mensch und Maschine), damit ein Status existiert.
- User Stories und Beispiele bei den Anforderungsspezifikationen können helfen.
- Bilder (multi-modale Eingabe) sind extrem gut geeignet, um Design und sonstige Anforderungen zu besprechen.
- Die Nutzung des geteilten Terminals und des Problems-Tabs ermöglicht dabei eine effektive Echtzeitkollaboration.
- Git sollte systematisch genutzt werden.
- Behalte die Realität im Blick - automatisch und auch sonst ;)
- Kleinschrittige Iterationen, Präzision, systematische Regeln und der Einbezug von Best-Practices helfen, um auch komplexere Projekte besser zu kontrollieren.
Die hier vorgestellten Best Practices basieren auf praktischer, individueller Erfahrung. Für jeden müssen sie nicht funktionieren.
Man sagt: Wer dumm fragt, bekommt auch dumme Antworten
… Naja … so in etwa verhält es sich mit Prompts.
Schlechte oder ungenaue Kommunikation führt nicht immer zum gewünschten Ziel bei der Interaktion mit generativen Programmierwerkzeugen. Tools wie Windsurf können unglaublich nützlich sein, aber auch unglaublich nervig. Man kann tolle Ergebnisse erzielen, aber auch frustriert und ergebnislos mit dem Agent in einem Rabbit-Hole verschwinden.
Hier hilft nur eines: die individuelle Erfahrung. Mit KI muss man den praktischen Umgang üben. Dies ist vermutlich der wichtigste Tipp an dieser Stelle.
Weiterführende Links:
Weitere Beiträge

Das Jahr 2021 war auch das Jahr des NFT-Hypes. Hier ein kleiner Erfahrungsbericht und Ausblick auf die Potentiale des Konzepts der non-fungible Token.

Ein Kommentar zu KI, dem Digital-Standort Deutschland und dem Luxus, viele Probleme zu haben …